

You may have a dataset and a purpose. Between them lies essentially the most crucial and time-consuming section of any machine studying venture: knowledge preprocessing.
Feeding uncooked, messy knowledge straight into an algorithm is a assured path to failure. The standard of your mannequin shouldn’t be decided by the complexity of the algorithm you select, however by the standard of the information you feed it.
This information is a step-by-step breakdown of the important preprocessing duties. We is not going to waste time on summary principle. As a substitute, we’ll give attention to the sensible sequence of operations you need to carry out to rework chaotic, real-world knowledge right into a clear, structured format that provides your mannequin its finest probability at success.
Step 1: First Factor to Do – Break up Your Knowledge
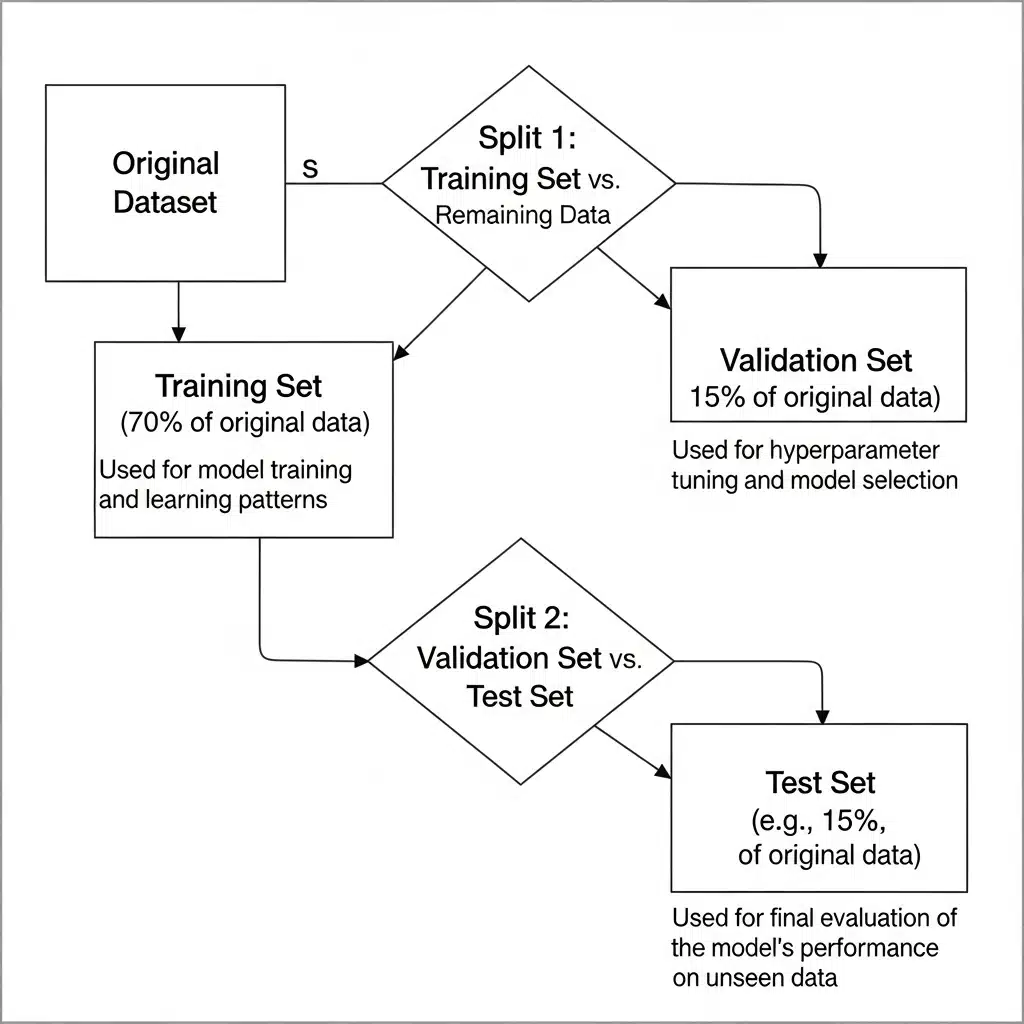
Earlier than you contact, clear, and even have a look at your knowledge too intently, break up it. You want separate coaching, validation, and testing units.
- Coaching Set: The majority of your knowledge. The mannequin learns from this.
- Validation Set: Used to tune your mannequin’s hyperparameters and make choices throughout coaching. It’s a proxy for unseen knowledge.
- Check Set: Stored in a vault, untouched till the very finish. That is for the ultimate, unbiased analysis of your skilled mannequin.
Why break up first?
To stop knowledge leakage. Knowledge leakage is when info from outdoors the coaching dataset is used to create the mannequin. If you happen to calculate the imply of a function utilizing the complete dataset after which use that to fill lacking values in your coaching set, your mannequin has already “seen” the take a look at knowledge. Its efficiency might be artificially inflated, and it’ll fail in the actual world.
Break up first, then do all of your preprocessing calculations (like discovering the imply, min, max, and many others.) solely on the coaching set. Then, apply those self same transformations to the validation and take a look at units.
A standard break up is 70% for coaching, 15% for validation, and 15% for testing, however this may change. For big datasets, you would possibly use a 98/1/1 break up as a result of 1% remains to be a statistically important variety of samples. For time-series knowledge, you don’t break up randomly. Your take a look at set ought to all the time be “sooner or later” relative to your coaching knowledge to simulate a real-world state of affairs.
Step 2: Knowledge Cleansing
Actual-world knowledge is messy. It has lacking values, outliers, and incorrect entries. Your job is to scrub it up.
Dealing with Lacking Values
Most machine studying algorithms can’t deal with lacking knowledge. You may have a couple of choices, and “simply drop it” isn’t all the time the very best one.
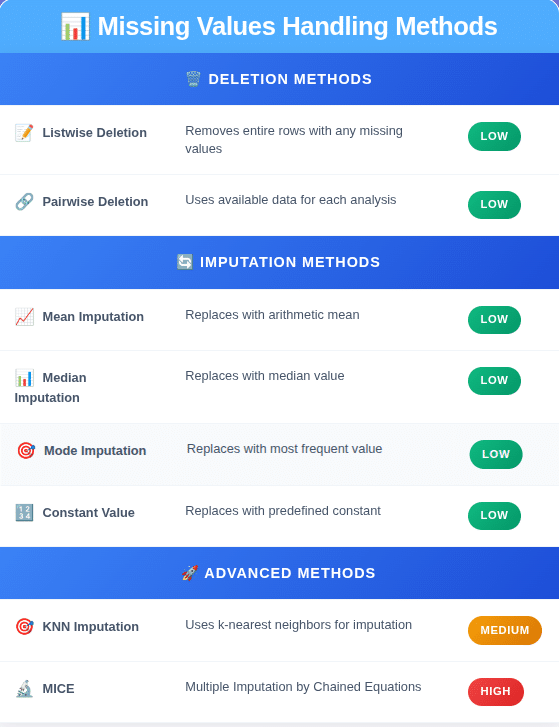
Deletion:
- Listwise Deletion (Drop Rows): If a row has a number of lacking values, you delete the complete row. That is easy however dangerous. When you have plenty of lacking knowledge, you would find yourself throwing away an enormous chunk of your dataset.
- Pairwise Deletion (Drop Columns): If a column (function) has a excessive share of lacking values (e.g., > 60-70%), it may be ineffective. Deleting the complete column could be a legitimate technique.
Imputation (Filling in Values):
That is normally the higher method, however it’s a must to watch out.
- Imply/Median/Mode Imputation: Substitute lacking numerical values with the imply or median of the column. Use the median if the information has plenty of outliers, because the imply is delicate to them. For categorical options, use the mode (essentially the most frequent worth). It is a primary method and might scale back variance in your knowledge.
- Fixed Worth Imputation: Generally a lacking worth has a that means. For instance, a lacking Garage_Finish_Date would possibly imply the home has no storage. On this case, you may fill the lacking values with a continuing like “None” or 0. For numerical options, you would impute with a price far outdoors the traditional vary, like -1, to let the mannequin realize it was initially lacking.
- Superior Imputation (KNN, MICE): Extra advanced strategies use different options to foretell the lacking values. Ok-Nearest Neighbors (KNN) imputation finds the ‘ok’ most comparable knowledge factors and makes use of their values to impute the lacking one. A number of Imputation by Chained Equations (MICE) is a extra strong methodology that creates a number of imputed datasets and swimming pools the outcomes. These are computationally dearer however typically extra correct.
A great apply is to create a brand new binary function that signifies whether or not a price was imputed. For a function age, you’d create age_was_missing. This lets the mannequin be taught if the truth that the information was lacking is itself a predictive sign.
Step 3: Dealing with Categorical Knowledge
Fashions perceive numbers, not textual content. You must convert categorical knowledge like “Colour” or “Metropolis” right into a numerical format.
Label Encoding
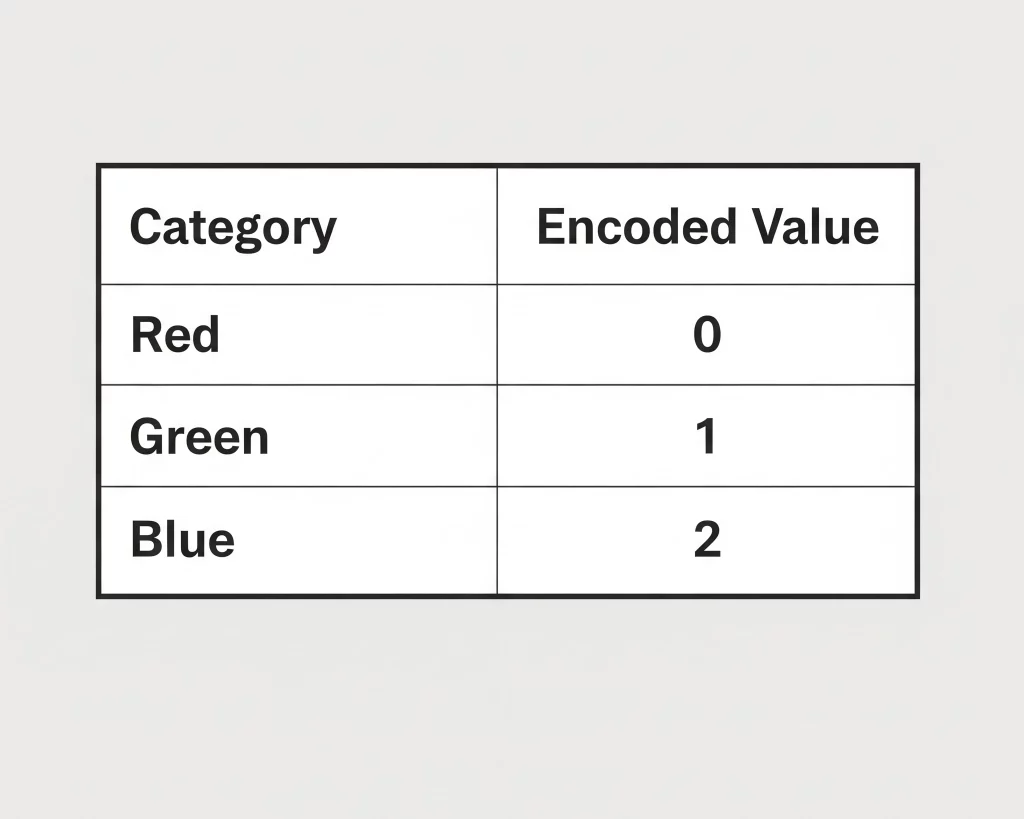
- What it’s: Assigns a novel integer to every class. Instance: {‘Crimson’: 0, ‘Inexperienced’: 1, ‘Blue’: 2}.
- When to make use of it: Just for ordinal variables, the place the classes have a significant order. For instance, {‘Low’: 0, ‘Medium’: 1, ‘Excessive’: 2}.
- When NOT to make use of it: For nominal variables the place there isn’t a intrinsic order, like colours or cities. Utilizing it right here introduces a man-made relationship; the mannequin would possibly assume Blue (2) is “better” than Inexperienced (1), which is meaningless and can harm efficiency.
One-Scorching Encoding
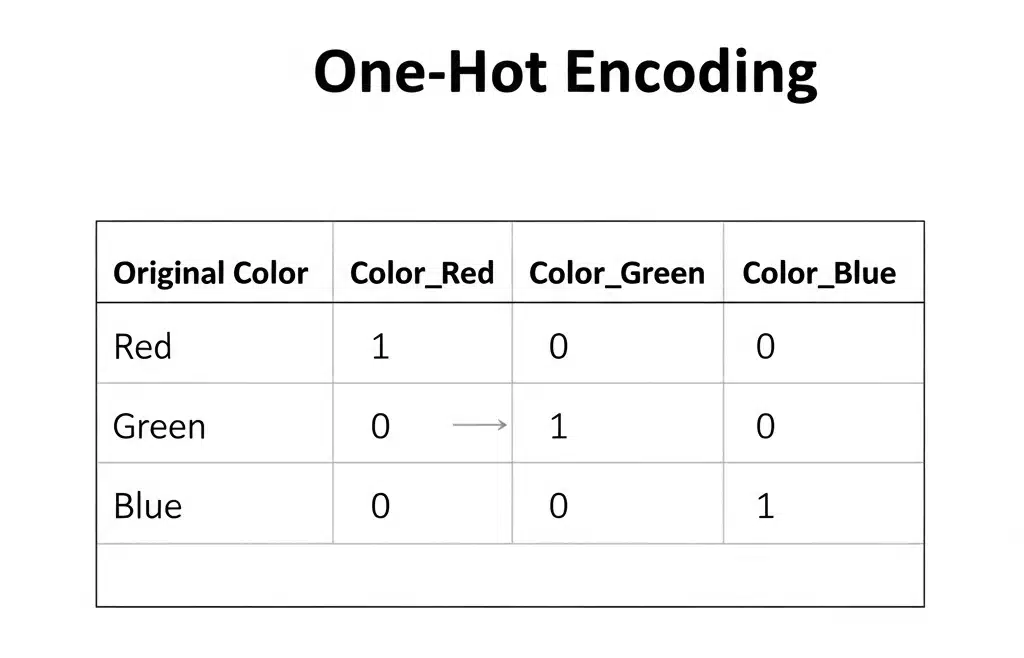
- What it’s: Creates a brand new binary (0 or 1) column for every class. If the unique function was “Colour” with classes Crimson, Inexperienced, and Blue, you get three new columns: Color_Red, Color_Green, and Color_Blue. For a “Crimson” knowledge level, Color_Red can be 1, and the opposite two can be 0.
- When to make use of it: That is the usual method for nominal categorical knowledge. It removes the ordinal relationship drawback.
- The Draw back (Curse of Dimensionality): If a function has many classes (e.g., 100 totally different cities), one-hot encoding will create 100 new columns. This could make your dataset big and sparse, an issue often called the “curse of dimensionality,” which may make it more durable for some algorithms to carry out effectively.
Different Encoding Strategies
For top-cardinality options (many classes), you may contemplate:
- Goal Encoding: Replaces every class with the typical worth of the goal variable for that class. That is highly effective however has a excessive threat of overfitting, so it must be applied rigorously (e.g., utilizing cross-validation).
- Function Hashing (The “Hashing Trick”): Makes use of a hash operate to map a probably giant variety of classes to a smaller, mounted variety of options. It’s memory-efficient however can have hash collisions (totally different classes mapping to the identical hash).
Step 4: Function Scaling – Placing Every little thing on the Identical Stage
Algorithms that use distance calculations (like KNN, SVM, and PCA) or gradient descent (like linear regression and neural networks) are delicate to the size of options. If one function ranges from 0-1 and one other from 0-100,000, the latter will dominate the mannequin. You must deliver all options to a comparable scale.
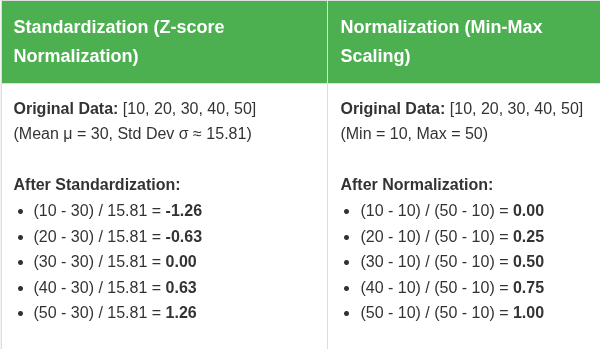
Standardization (Z-score Normalization)
- What it does: Transforms the information to have a imply of 0 and a normal deviation of 1. The components is (x – imply) / std_dev.
- When to make use of it: That is the go-to methodology for a lot of algorithms, particularly when your knowledge is roughly usually distributed. It doesn’t bind values to a selected vary, which makes it much less delicate to outliers. PCA, for instance, typically requires standardization.
Normalization (Min-Max Scaling)
- What it does: Rescales the information to a hard and fast vary, normally 0 to 1. The components is (x – min) / (max – min).
- When to make use of it: Good for algorithms that don’t assume any distribution, like neural networks, as it may well assist with quicker convergence. Nevertheless, it’s very delicate to outliers. A single excessive worth can squash all the opposite knowledge factors into a really small vary.
- Which one to decide on? There’s no single proper reply. Standardization is usually a safer default selection. When you have a purpose to sure your knowledge or your algorithm requires it, use normalization. When doubtful, you may all the time strive each and see which performs higher in your validation set. Tree-based fashions like Determination Bushes and Random Forests will not be delicate to function scaling.
Learn in Element: Knowledge Normalization and Standardization
Step 5: Function Engineering – Creating New Data
That is the place area data and creativity are available in. It’s the method of making new options from current ones to assist your mannequin be taught higher.
- Interplay Options: Mix two or extra options. For instance, when you have Top and Weight, you may create a BMI function (Weight / Top^2). You would possibly discover that the interplay between Temperature and Humidity is extra predictive of gross sales than both function alone.
- Polynomial Options: Create new options by elevating current options to an influence (e.g., age^2, age^3). This can assist linear fashions seize non-linear relationships.
- Time-Primarily based Options: When you have a datetime column, don’t simply depart it. Extract helpful info like hour_of_day, day_of_week, month, or is_weekend. For cyclical options like hour_of_day, merely utilizing the quantity isn’t best as a result of hour 23 is near hour 0. A greater method is to make use of sine and cosine transformations to signify the cyclical nature.
- Binning: Convert a steady numerical function right into a categorical one. For instance, you may convert age into classes like 0-18, 19-35, 36-60, and 60+. This could generally assist the mannequin be taught patterns in particular ranges.
Function engineering is usually an iterative course of. You create options, prepare a mannequin, analyze the outcomes, after which return to create extra knowledgeable options.
Last Phrase
Knowledge preprocessing shouldn’t be a inflexible guidelines; it’s a considerate course of that relies upon closely in your particular dataset and the issue you’re attempting to resolve. All the time doc the steps you’re taking and the explanations on your choices. This makes your work reproducible and simpler to debug when your mannequin inevitably does one thing sudden. Good preprocessing is the muse of a very good mannequin.